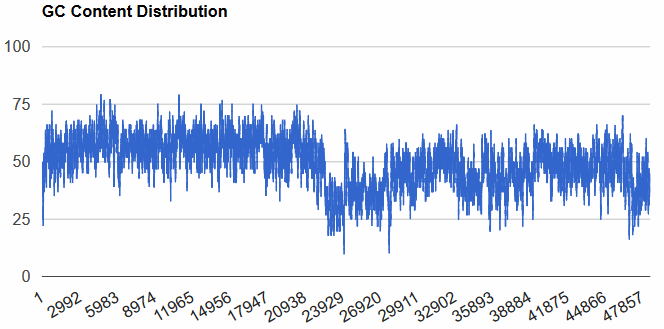
VecScreen (National Center for Biotechnology Information) - screens your DNA sequence for potential vector sequence. Well worth running before doing any other analysis.